Introduction: The Guardians of Uptime
Every time you refresh a webpage, send a message, or stream a video, there’s an invisible force ensuring that everything works seamlessly — no matter the hour, traffic surge, or outage. That force is the Site Reliability Engineer (SRE).
Born at Google in the early 2000s, the SRE role has become essential to how modern digital systems operate. In simple terms, an SRE ensures that a company’s software runs reliably, efficiently, and at scale.
They are the bridge between development and operations, merging coding skills with system administration expertise to keep services running even when the unexpected happens.
What Exactly Does a Site Reliability Engineer Do?
A Site Reliability Engineer takes the best practices from software engineering — like automation, version control, and continuous integration — and applies them to infrastructure and operations.
Their mission is simple but profound:
➡️ Keep systems available, performant, and resilient.
While traditional system administrators manually maintain servers, SREs automate everything — from deployments and scaling to incident response and monitoring.
Typical responsibilities include:
- Building tools that automatically detect and fix outages.
- Creating and managing CI/CD pipelines.
- Monitoring performance metrics (latency, error rates, uptime).
- Writing code to eliminate repetitive operational tasks.
- Collaborating with developers to make applications more reliable.
- Managing cloud resources and containers (AWS, GCP, Kubernetes).
In essence, an SRE’s motto is:
“If you have to do it twice, automate it.”
How the SRE Role Differs from DevOps
At first glance, SRE and DevOps might sound similar — and they do overlap — but they aren’t the same thing.
- DevOps is a culture or philosophy that emphasizes collaboration between developers and operations teams.
- SRE is an implementation of that philosophy, with specific engineering practices and metrics.
For example:
- DevOps focuses on continuous delivery and faster releases.
- SRE focuses on system reliability and minimizing downtime.
SREs measure success using metrics like:
- SLA (Service Level Agreement): Target reliability set with customers.
- SLO (Service Level Objective): The internal reliability goal (e.g., 99.9% uptime).
- SLI (Service Level Indicator): The actual measurement (e.g., response time, availability).
This data-driven approach ensures that reliability isn’t just a goal — it’s quantified, tracked, and improved over time.
Core Skills and Technical Expertise
To thrive as an SRE, one must wear multiple hats — software engineer, systems architect, and detective.
Key technical skills include:
- Programming & Scripting: Python, Go, Bash, or Ruby to automate processes.
- Cloud Platforms: AWS, Google Cloud Platform (GCP), Microsoft Azure.
- Containers & Orchestration: Docker, Kubernetes, Helm.
- Infrastructure as Code (IaC): Terraform, Ansible, or CloudFormation.
- Monitoring & Observability: Prometheus, Grafana, Datadog, New Relic, ELK Stack.
- CI/CD Systems: Jenkins, GitLab CI, ArgoCD, CircleCI.
- Networking: DNS, load balancing, reverse proxies, SSL/TLS.
- Incident Management: PagerDuty, Opsgenie, and structured postmortems.
But beyond tools, the real skill lies in thinking systemically — predicting how a system behaves under pressure and designing for failure before it happens.
Educational Pathway: How to Become an SRE
Most Site Reliability Engineers hold degrees in Computer Science, Software Engineering, or Information Technology, but the field is open to anyone with strong coding and infrastructure skills.
Academic Path:
- Bachelor’s Degree: In CS, IT, or related engineering disciplines.
- Master’s (Optional): Some pursue advanced studies in distributed systems or cloud computing, but it’s not mandatory.
Alternative Routes:
- Bootcamps focused on Cloud Engineering or DevOps automation.
- Self-learning through hands-on labs and certifications.
Recommended Certifications:
- Google Professional Cloud DevOps Engineer
- AWS Certified DevOps Engineer – Professional
- Microsoft Certified: DevOps Engineer Expert
- Kubernetes Certified Administrator (CKA)
- HashiCorp Terraform Associate
Many SREs enter from adjacent roles — such as backend developers, system administrators, or network engineers — and grow into the reliability space by mastering automation and scalability.
A Day in the Life of an SRE
The workday of an SRE can vary based on company size and system complexity. But it typically involves a mix of proactive engineering and reactive problem-solving.
Morning: Review system dashboards, analyze overnight alerts, and attend stand-ups with development teams.
Midday: Deploy new releases or infrastructure updates using CI/CD pipelines.
Afternoon: Write scripts to automate routine maintenance, optimize load balancers, or refine monitoring thresholds.
Evening (sometimes): Respond to incidents, lead root-cause analysis, or update documentation.
While the occasional 3 a.m. alert is part of the job, the goal is to reduce human toil — designing systems so reliable that human intervention becomes increasingly rare.
Tools of the Trade
Every SRE relies on a toolkit to build, monitor, and stabilize systems.
Common Tools Include:
- Automation: Ansible, Terraform, Puppet.
- Containers & Clusters: Kubernetes, Docker, OpenShift.
- Monitoring: Prometheus, Grafana, Datadog.
- Incident Response: PagerDuty, Sentry, Opsgenie.
- Logging & Tracing: ELK Stack, Jaeger, Zipkin.
- Collaboration: Slack, Jira, Confluence, GitHub Actions.
The magic of an SRE lies not just in knowing these tools — but in integrating them into self-healing, observable systems.
Industries and Opportunities
SREs are needed anywhere uptime matters — which, in the digital world, means everywhere.
Top industries hiring SREs include:
- Tech and SaaS Companies – Google, Meta, Amazon, Microsoft.
- Finance and Fintech – where downtime can cost millions per second.
- E-commerce – ensuring websites stay fast and secure during traffic spikes.
- Streaming & Gaming – maintaining real-time, low-latency systems.
- Healthcare & Government IT – where reliability equals trust and safety.
Many SREs also work for consulting firms or startups, helping design scalable infrastructure from day one.
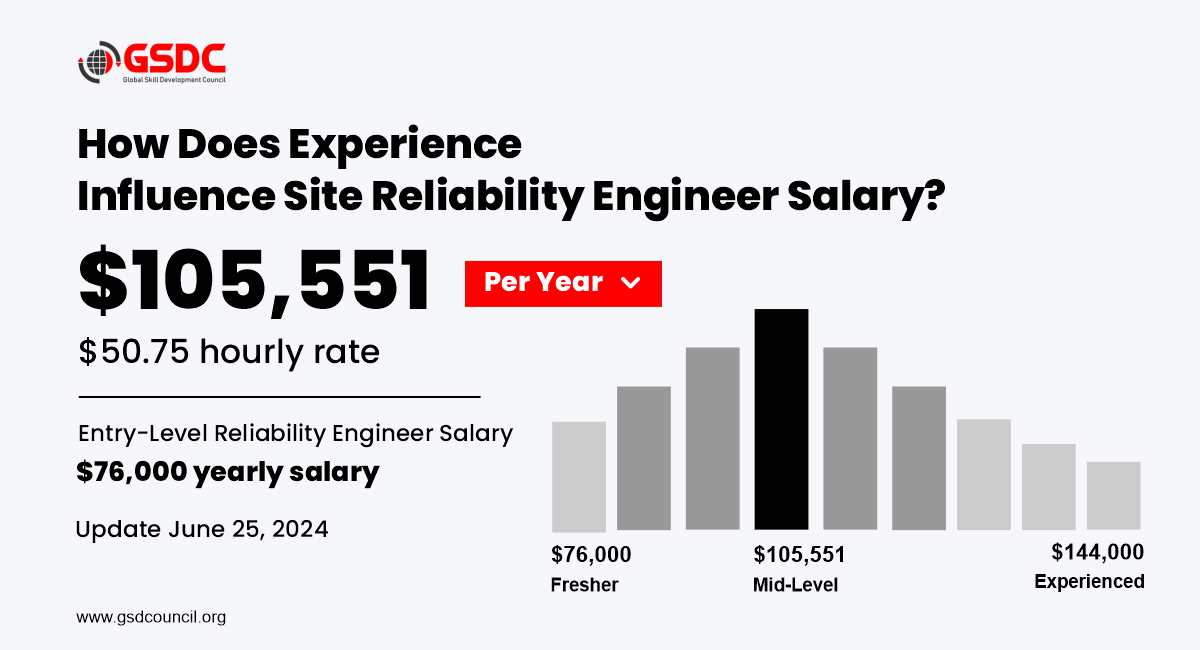
Career Outlook and Salary Potential
As of 2025, Site Reliability Engineers remain among the top 10 highest-paying tech jobs in the U.S.
Average Salaries (2025 estimates):
- Entry-level: $95,000 – $120,000
- Mid-level: $120,000 – $160,000
- Senior / Lead SRE: $160,000 – $200,000+
- Principal or SRE Manager: $200,000 – $250,000+
With the rise of cloud-native architecture, AI workloads, and global-scale applications, SREs are now mission-critical hires — and demand is only growing.
Challenges of Being an SRE
The job isn’t all smooth sailing. The same systems that must never go down can also create immense pressure.
Common challenges include:
- Alert Fatigue: Too many notifications can reduce focus.
- Balancing Speed vs. Stability: Shipping features fast without breaking uptime.
- Legacy Systems: Maintaining reliability while modernizing infrastructure.
- On-Call Stress: Managing round-the-clock system responsibility.
The best SREs combat these challenges with discipline, observability, and collaboration — knowing when to automate, when to escalate, and when to simplify.
The Future of Site Reliability Engineering
As systems get more distributed and AI-driven, SREs are evolving from operations guardians to architects of reliability automation.
Key trends shaping the next decade:
- AI-Driven Incident Management: Predictive monitoring using machine learning.
- NoOps & Self-Healing Systems: Fully automated recovery from failures.
- Chaos Engineering: Intentionally breaking systems to build resilience.
- Platform Engineering: Abstracting infrastructure to empower developers.
- Edge Reliability: Extending uptime guarantees beyond the cloud to edge devices.
In other words, tomorrow’s SREs won’t just maintain systems — they’ll design ecosystems that manage themselves.
Conclusion: Reliability is the New Innovation
Behind every app that “just works” is a team of SREs ensuring it never stops working.
They represent the perfect balance of software craftsmanship and operational discipline — a blend that’s critical in an era where even seconds of downtime can impact millions.
As technology continues to evolve, Site Reliability Engineers will remain the unsung heroes of digital stability, quietly keeping the internet running, one automation at a time.